개발한 모델 서빙하기¶
개발 환경에서 학습한 머신러닝 모델을 프로덕션 환경에 배포하고, 외부에서 추론 요청을 받을 수 있도록 서비스화하는 전체 과정을 안내합니다. 이 가이드를 따라 추론 엔드포인트를 생성하고, 모델을 배포한 후, 실제 추론 요청까지 실행해보세요.
시작하기 전에¶
사전 준비사항
- 배포할 모델이 프로젝트 볼륨에 준비되어 있어야 합니다.
- API 키가 발급되어 있어야 추론 요청이 가능합니다. API 키 발급 방법은 API 키 관리를 참고하세요.
1단계: 추론 엔드포인트 생성¶
외부에서 모델을 호출할 수 있는 엔드포인트를 먼저 생성합니다.
-
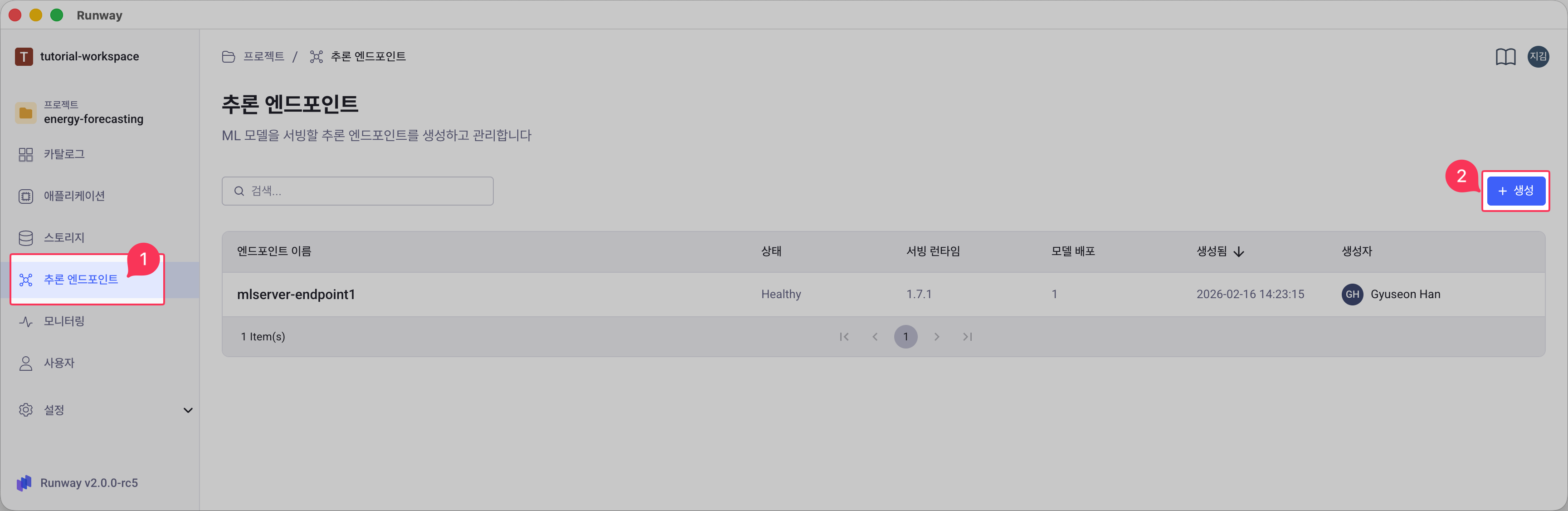
프로젝트 화면 왼쪽 사이드바에서 추론 엔드포인트 메뉴를 클릭합니다.
-
오른쪽 상단의 + 생성 버튼을 클릭합니다.
-
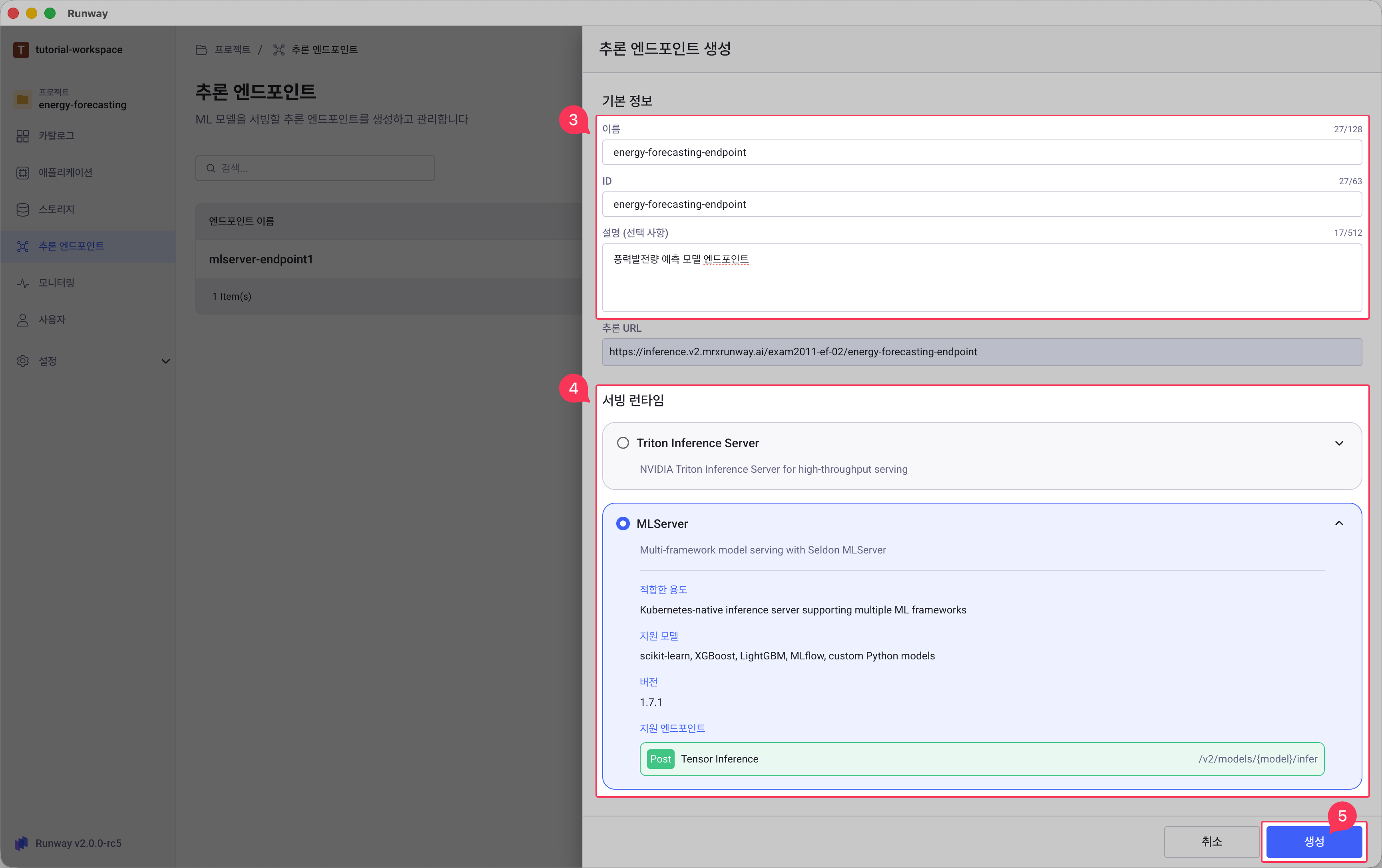
기본 정보를 입력합니다.
-
기본 정보
- 이름: 엔드포인트를 식별할 수 있는 이름 (예:
energy-forecasting-endpoint) -
ID: 입력한 이름에 따라 자동 추천되며, 생성 시 수정 가능 (3-53자, 영문 소문자, 숫자, 하이픈(-)만 사용 가능)
추론 URL 미리보기
ID를 입력하면 생성될 엔드포인트 추론 URL을 미리 확인할 수 있습니다. ID는 URL에 직접 반영되며 생성 후 변경할 수 없으므로, 생성 전 미리보기로 URL 형태를 확인하세요.
-
설명 (선택): 엔드포인트에 대한 설명
- 이름: 엔드포인트를 식별할 수 있는 이름 (예:
-
-
서빙 런타임을 선택합니다.
- 모델 유형에 맞는 서빙 런타임을 선택합니다.
- Triton Inference Server (v25.12-py3): TensorRT, PyTorch, TensorFlow, ONNX, OpenVINO, Python backends
- MLServer (v1.7.1): scikit-learn, XGBoost, LightGBM, MLflow, Custom Python models
런타임 선택 주의
서빙 런타임은 엔드포인트 생성 후 변경할 수 없습니다. 모델 유형에 맞게 신중하게 선택하세요. 자세한 내용은 서빙 런타임 선택 가이드를 참고하세요.
-
생성 버튼을 클릭합니다.
-
엔드포인트가 생성되고 상태가 Healthy가 되면 다음 단계로 진행합니다.
추론 엔드포인트 상세 설명
엔드포인트 생성 및 관리에 대한 자세한 내용은 엔드포인트 생성 및 관리를 참고하세요.
2단계: 모델 배포¶
생성된 엔드포인트에 실제 모델을 배포합니다.
-
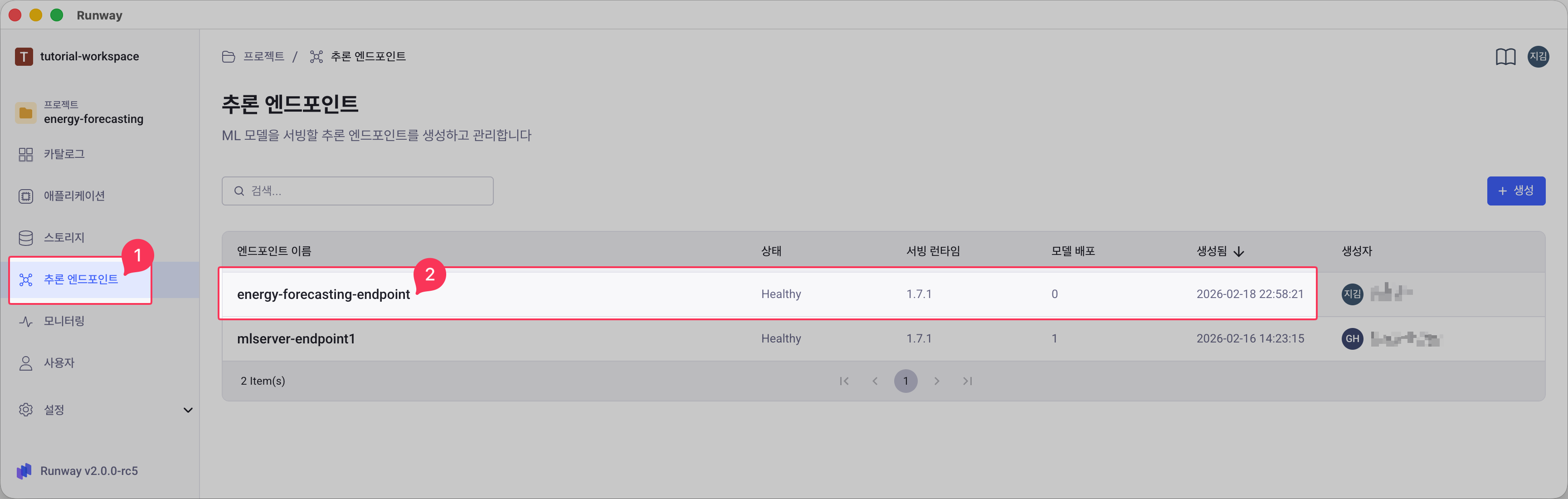
프로젝트에서 추론 엔드포인트 메뉴로 이동합니다.
-
엔드포인트 목록에서 방금 생성한 엔드포인트를 클릭합니다.
-
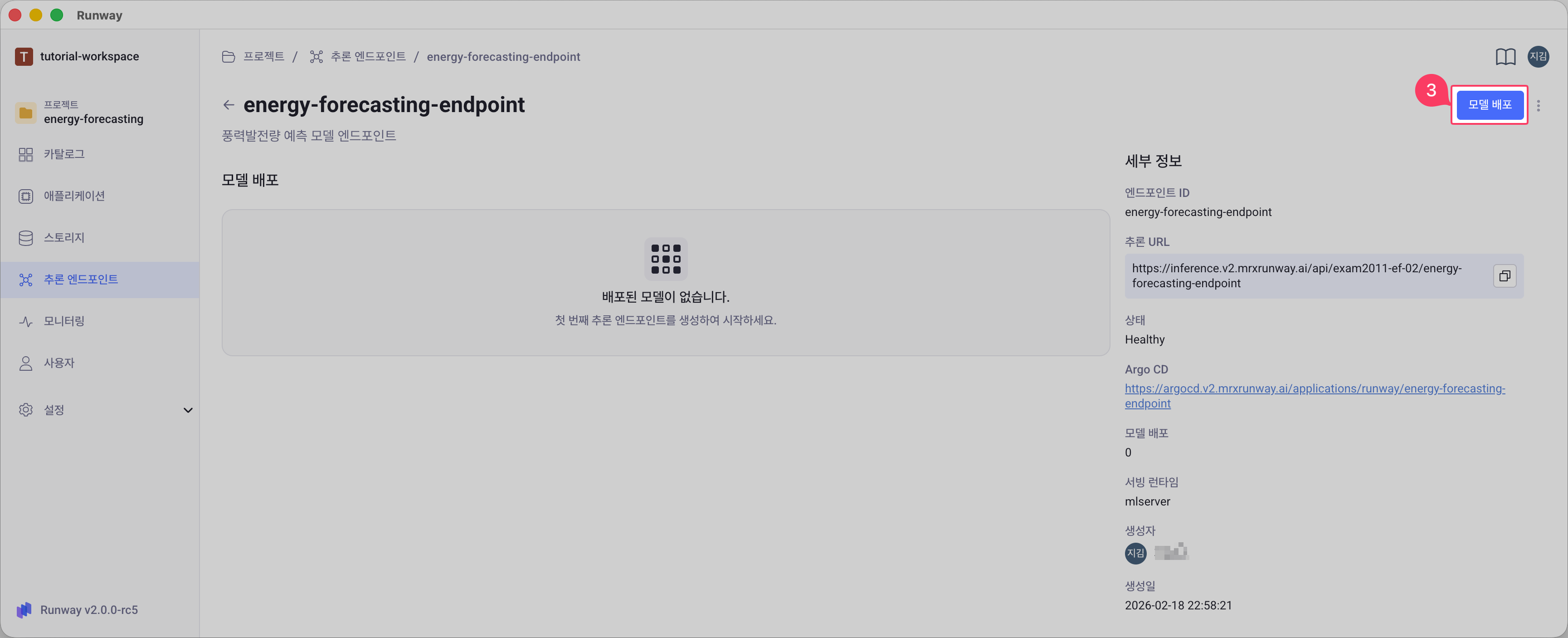
엔드포인트 상세 화면에서 오른쪽 상단의 모델 배포 버튼을 클릭합니다.
-
모델 배포 사이드 패널에서 기본 정보를 입력합니다.
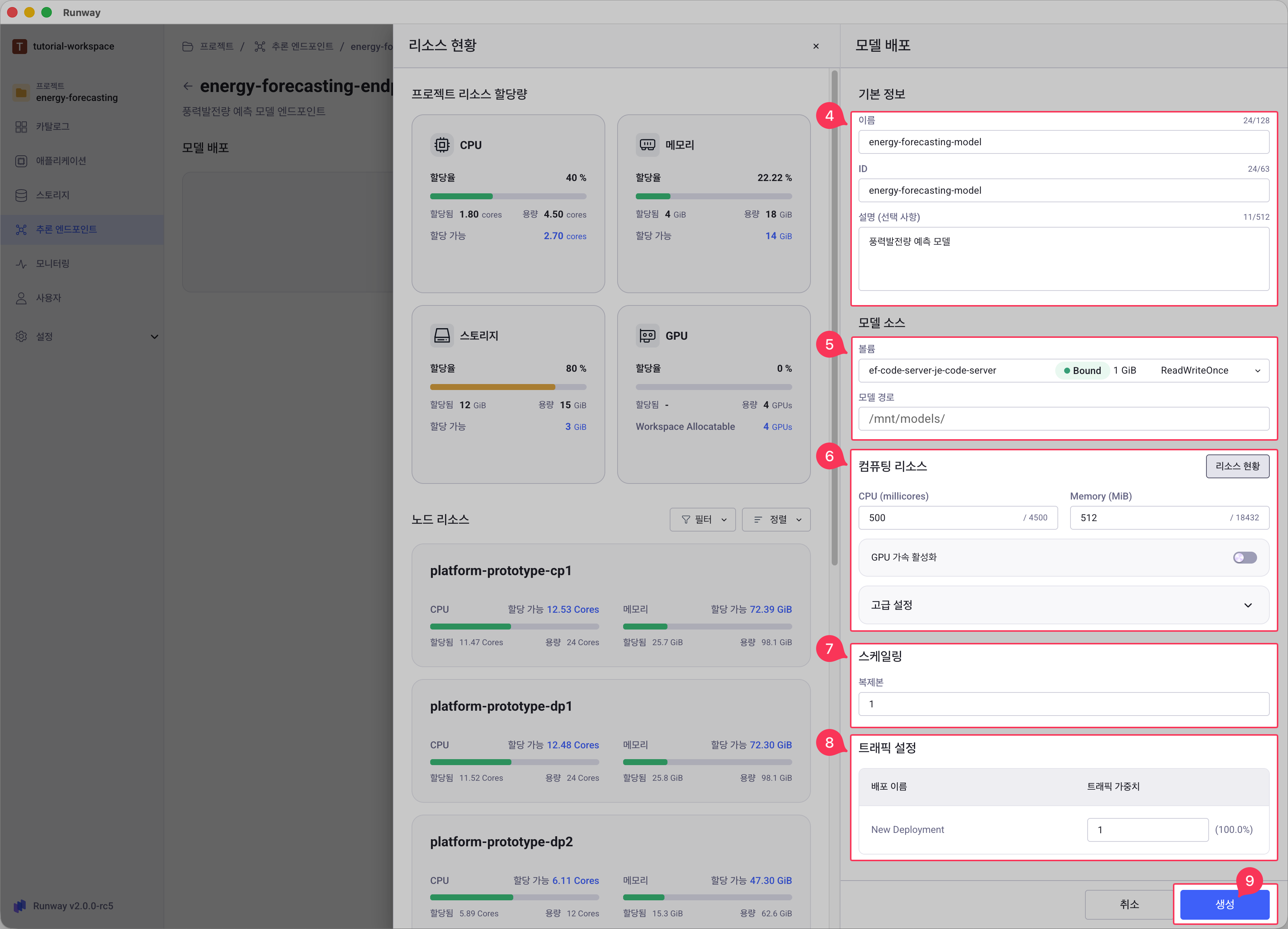
- 이름: 배포 모델을 식별할 수 있는 이름
- ID: 입력한 이름에 따라 자동 추천되며, 생성 시 수정 가능
- 설명 (선택): 배포할 모델에 대한 설명
-
모델 소스를 선택합니다.
- 볼륨: 드롭다운 목록에서 모델이 저장된 프로젝트 볼륨 선택
- 모델 경로 (선택):
- 볼륨 내에서 모델이 저장된 경로를 입력(예:
llama-3.1-70b-instruct) - 모델 경로에는 볼륨의 기본 위치인
/mnt/models/경로가 고정 값으로 표시됩니다.
- 볼륨 내에서 모델이 저장된 경로를 입력(예:
-
컴퓨팅 리소스를 입력합니다.
- CPU: 할당할 CPU 용량 (millicores 단위, 정수 입력, 예: 500, 1000, 2000)
- Memory: 할당할 메모리 용량 (최소 64 MiB 이상, MiB 단위, 정수 입력, 예: 512, 1024, 5120)
- GPU 가속 활성화 (선택): GPU가 필요한 모델의 경우 토글을 활성화하고, GPU 리소스 설정
- 고급 설정 (선택): 공유 메모리를 설정할 수 있습니다. 자세한 내용은 공유 메모리 설정을 참고하세요.
-
스케일링 값을 입력합니다.
- 복제본 수: 동시에 실행할 모델 인스턴스 개수 (기본값: 1, 최대값: 100)
-
트래픽 설정 값을 입력합니다.
- 첫 배포의 경우 자동으로 100% 트래픽이 할당됩니다.
-
생성 버튼을 클릭합니다.
모델 배포 상세 설명
모델 배포 및 관리에 대한 자세한 내용은 모델 배포 및 관리를 참고하세요.
3단계: 추론 요청 테스트¶
배포된 모델에 실제 추론 요청을 보내봅니다.
엔드포인트 URL 확인¶
-
엔드포인트 상세 화면에서 추론 URL을 복사합니다.
-
아래 방법을 활용하여 추론 요청 테스트를 진행합니다.
요청 데이터 수정 필요
아래 예시는 샘플 데이터입니다. 실제로는 배포한 모델의 입력 스펙에 맞게 데이터를 수정해야 합니다.
curl로 추론 요청¶
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <API-KEY-TOKEN>" \
-d '{
"inputs": [
{
"name": "input_data",
"shape": [1, 4],
"datatype": "FP32",
"data": [[1.0, 2.0, 3.0, 4.0]]
}
]
}' \
https://inference.<base-domain>/api/<project-id>/<endpoint-id>/v2/models/<model-name>/infer
Python으로 추론 요청¶
import requests
url = "https://inference.<base-domain>/api/<project-id>/<endpoint-id>/v2/models/<model-name>/infer"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API-KEY-TOKEN>"
}
data = {
"inputs": [
{
"name": "input_data",
"shape": [1, 4],
"datatype": "FP32",
"data": [[1.0, 2.0, 3.0, 4.0]]
}
]
}
response = requests.post(url, json=data, headers=headers)
print(response.json())
추론 요청 상세 정보
추론 요청에 대한 자세한 내용은 추론 요청을 참고하세요.