모델 배포 및 배포 전략¶
엔드포인트에 모델을 배포하고 운영하는 방법을 안내합니다. 프로젝트 볼륨에 저장된 모델을 배포하고, 여러 모델 버전을 동시에 운영하며, 트래픽 가중치를 조정하여 A/B 테스트나 카나리 배포를 수행할 수 있습니다.
프로젝트 > 추론 엔드포인트 메뉴 > (특정 엔드포인트) 선택
모델 배포란?¶
모델 배포는 엔드포인트에서 제공할 실제 모델 아티팩트를 지정하고 실행하는 단위입니다. 하나의 엔드포인트에 여러 모델을 배포하여 트래픽을 분산하거나 A/B 테스트를 수행할 수 있습니다.
모델 배포 방법¶
엔드포인트에 모델을 배포하는 방법을 안내합니다.
모델 소스 지원
모델 배포 시 모델 파일이 저장된 위치를 지정해야 합니다. 현재는 프로젝트 볼륨(Volume)만 모델 소스로 지원됩니다.
- 볼륨: 프로젝트에서 생성한 스토리지 볼륨에 저장된 모델을 로드합니다.
- 모델 파일은 사전에 볼륨에 업로드되어 있어야 합니다.
- 볼륨 생성 방법은 볼륨 생성 및 조회를 참고하세요.
-
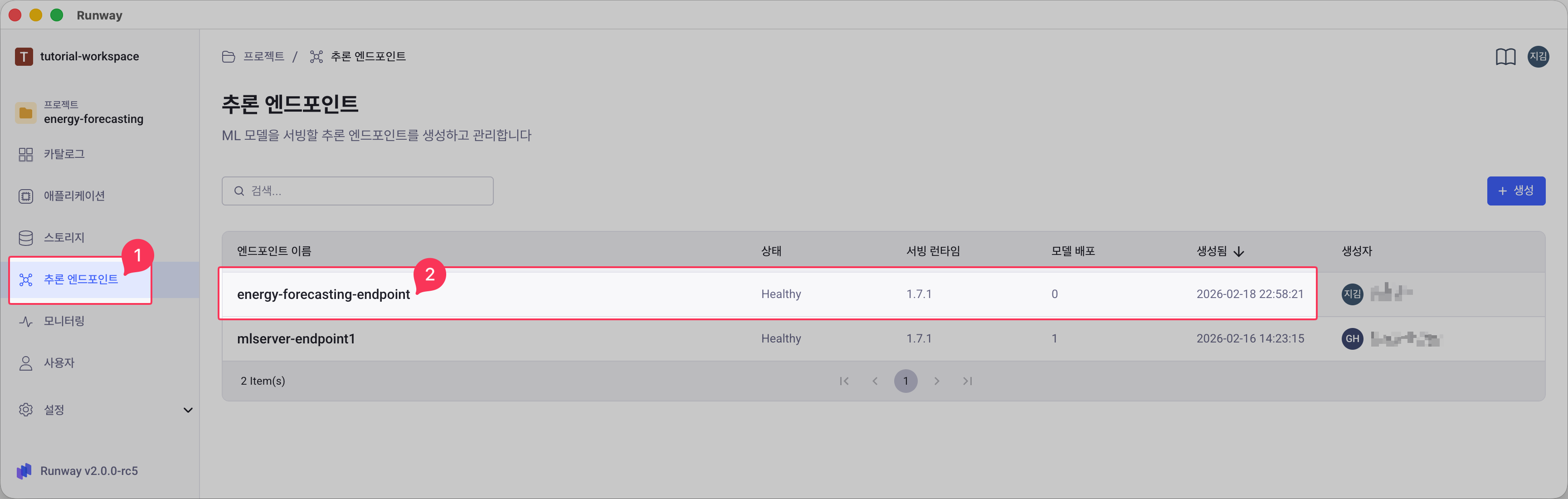
프로젝트 화면에서 추론 엔드포인트 메뉴로 이동합니다.
-
모델을 배포할 엔드포인트를 클릭합니다.
-
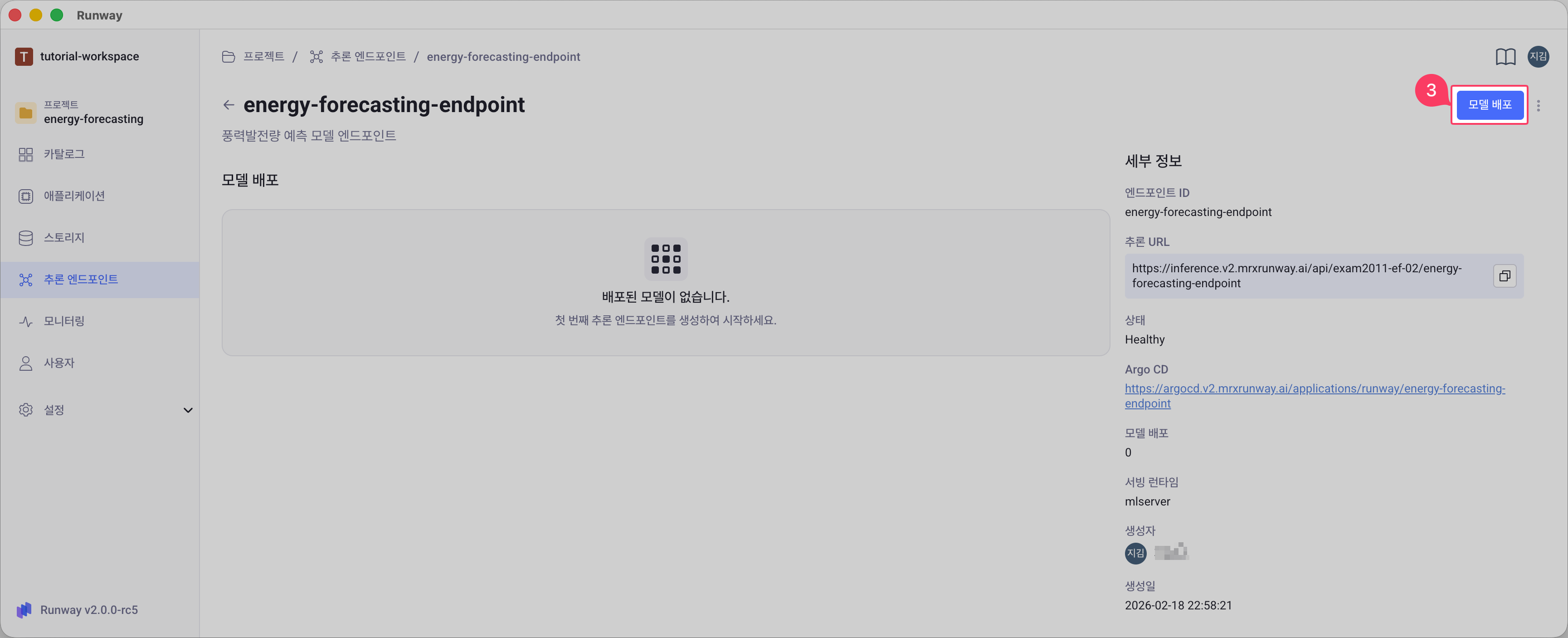
엔드포인트 상세 화면에서 오른쪽 상단의 모델 배포 버튼을 클릭합니다.
-
기본 정보를 입력합니다.
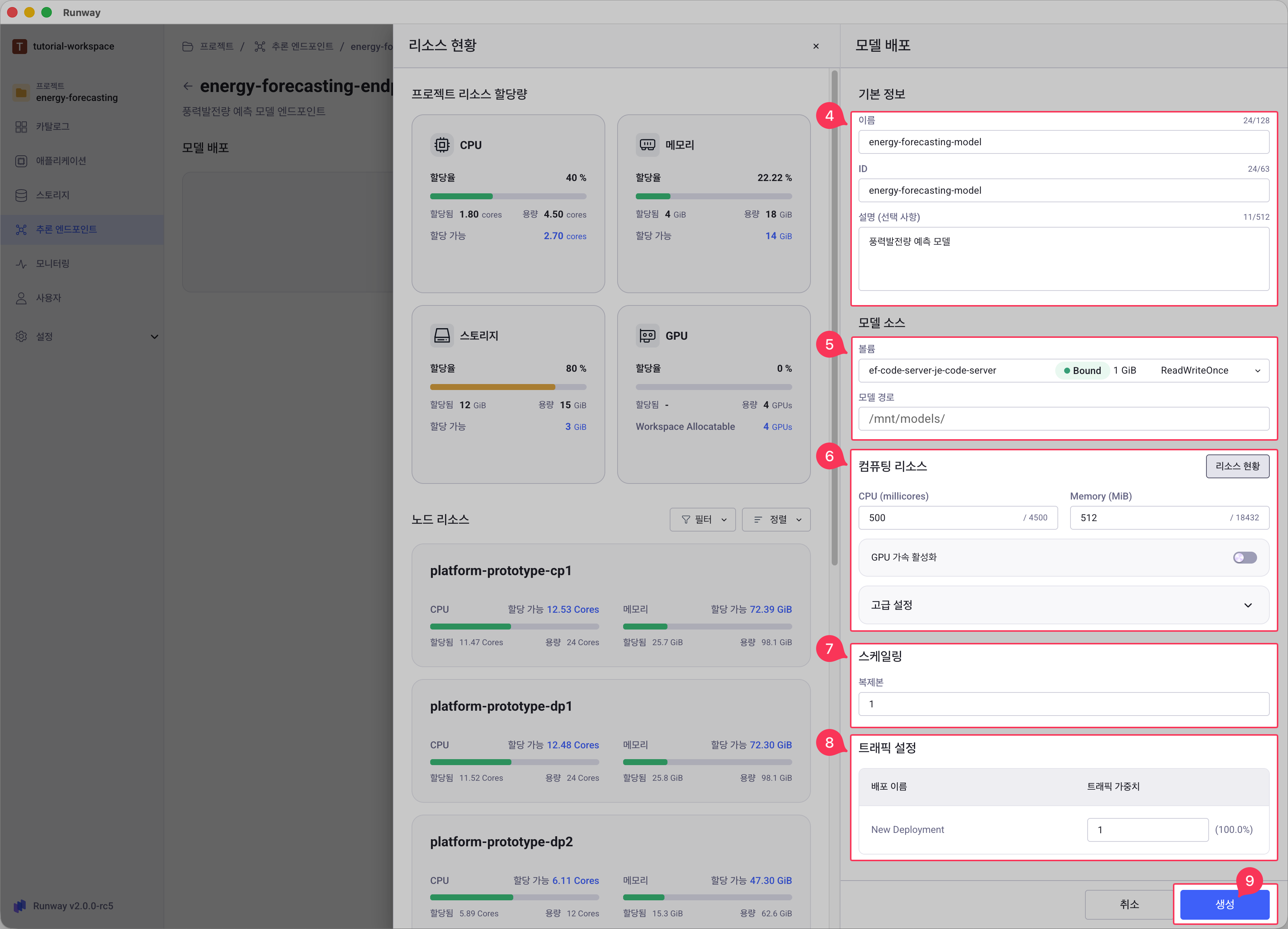
- 이름: 배포할 모델 이름을 입력합니다. (최대 128자)
- ID: 입력한 모델 이름에 따라 자동 추천되며, 생성 시에는 수정할 수 있습니다.
(3-63자, 영문 소문자, 숫자, 하이픈(-)만 사용 가능) - 설명 (선택): 배포할 모델에 대한 설명을 입력합니다.
-
모델 소스 영역에서 배포할 모델이 저장된 위치를 지정합니다.
-
볼륨: 드롭다운 목록에서 모델이 저장된 프로젝트 볼륨을 선택합니다.
-
모델 경로 (선택): 볼륨 내에서 모델이 저장된 경로를 입력합니다.
- 볼륨 루트에서 모델 폴더까지의 상대 경로를 입력합니다.
- 모델 경로에는 볼륨의 기본 위치인
/mnt/models/경로가 고정 값으로 표시됩니다. - 빈 값으로 두면 볼륨 최상위 경로(
/mnt/models/)를 사용합니다.
서빙 런타임별 모델 경로 해석 방식 차이
서빙 런타임에 따라 모델 경로를 해석하는 방식이 다릅니다.
MLServer — 경로를 모델 파일이 위치한 디렉토리로 직접 해석합니다.
→ 모델 경로 입력:볼륨 구조 예시: auto-mpg-model/ ← 모델 파일 디렉토리 MLmodel model.pklauto-mpg-modelTriton — 경로를 모델 저장소(repository) 루트로 해석합니다. 그 안에 모델명 디렉토리가 있어야 합니다.
→ 모델 경로 입력: (빈 값) — 볼륨 루트(볼륨 구조 예시: my-onnx-model/ ← 모델명 디렉토리 config.pbtxt 1/ model.onnx/mnt/models/)를 저장소 루트로 사용 -
-
컴퓨팅 리소스에서 모델 추론에 필요한 컴퓨팅 리소스를 할당합니다.
리소스 현황 확인 및 할당 가이드
리소스 현황 버튼을 클릭하면 현재 프로젝트의 리소스 현황을 확인할 수 있습니다.
- 모델 크기와 추론 복잡도에 따라 적절한 리소스를 할당하세요.
초기에는 작은 리소스로 시작하여 모니터링 후 조정하는 것을 권장합니다. - GPU는 딥러닝 모델이나 대규모 언어 모델에 필요합니다.
- 배포할 모델과 현재 잔여 리소스 양을 확인하여 적절한 리소스를 할당하고, 리소스 부족 시 관리자에게 문의하세요.
- CPU: 할당할 CPU 용량 (millicores 단위, 정수 입력, 예: 500, 1000, 2000)
-
Memory: 할당할 메모리 용량 (최소 64 MiB 이상, MiB 단위, 정수 입력, 예: 512, 1024, 5120)
-
GPU 가속 활성화: GPU가 필요한 모델의 경우 토글을 활성화합니다.
GPU 설정 방법
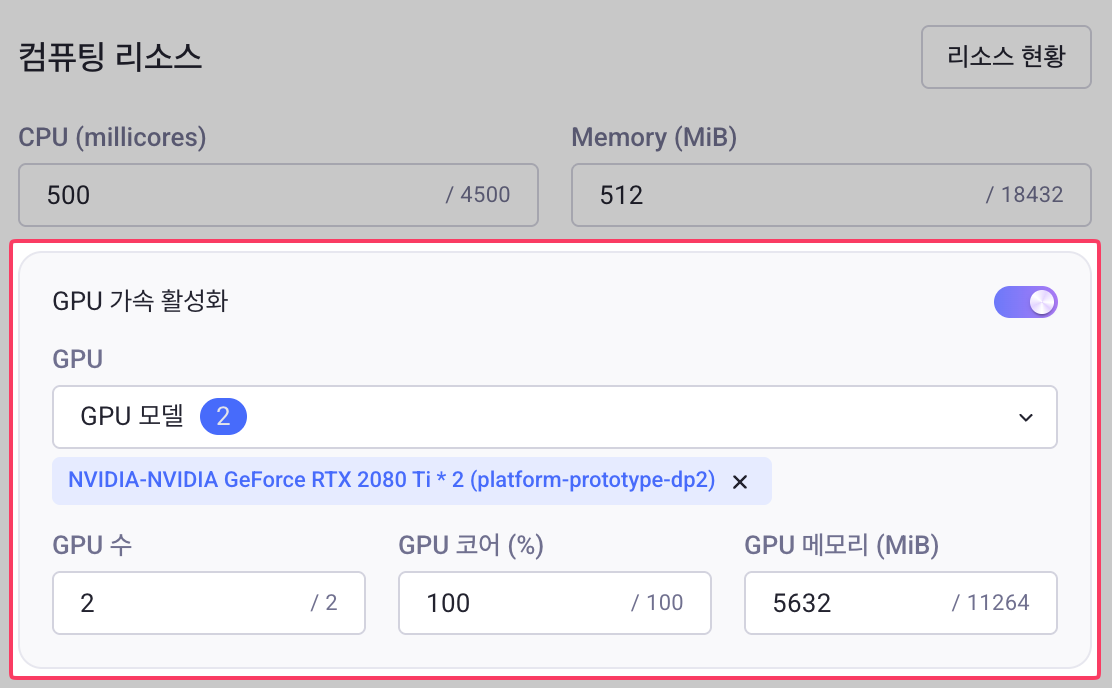
GPU 가속을 활성화하고 아래 항목을 설정합니다.
- GPU 모델 선택: 드롭다운 목록에서 사용 가능한 노드별 GPU 모델 목록을 확인하고 원하는 GPU를 선택합니다.
- GPU 수: 할당할 GPU 개수를 입력합니다.
- GPU 코어 (%): GPU 코어 사용률을 퍼센트로 지정합니다.
- GPU 메모리 (MiB): 할당할 GPU 메모리 용량을 입력합니다.
-
고급 설정(공유 메모리): 고급 설정을 열면 공유 메모리를 설정할 수 있습니다.
공유 메모리 설정
공유 메모리 설정는 컨테이너 내부의 프로세스 간 데이터를 빠르게 공유하기 위한 메모리 영역을 지정하는 것입니다.
자세한 설정 방법은 공유 메모리 설정을 참고하세요.
- 모델 크기와 추론 복잡도에 따라 적절한 리소스를 할당하세요.
-
스케일링 영역에서 트래픽에 대응하기 위한 복제본 수를 설정합니다.
- 복제본 수: 동시에 실행할 모델 인스턴스 개수 (기본값: 1, 최대값: 100)
-
트래픽 설정 영역에서 트래픽 가중치를 입력합니다.
트래픽 분배 전략
여러 모델 배포가 있는 경우 트래픽 분배 전략을 설정합니다.
첫 번째 배포
- 첫 배포의 경우 자동으로 100% 트래픽이 할당됩니다.
추가 배포
- 트래픽 비율을 조정하여 A/B 테스트나 점진적 롤아웃을 수행할 수 있습니다.
- 예: 기존 모델 80%, 새 모델 20%
-
모든 정보를 입력한 후 생성 버튼을 클릭합니다.
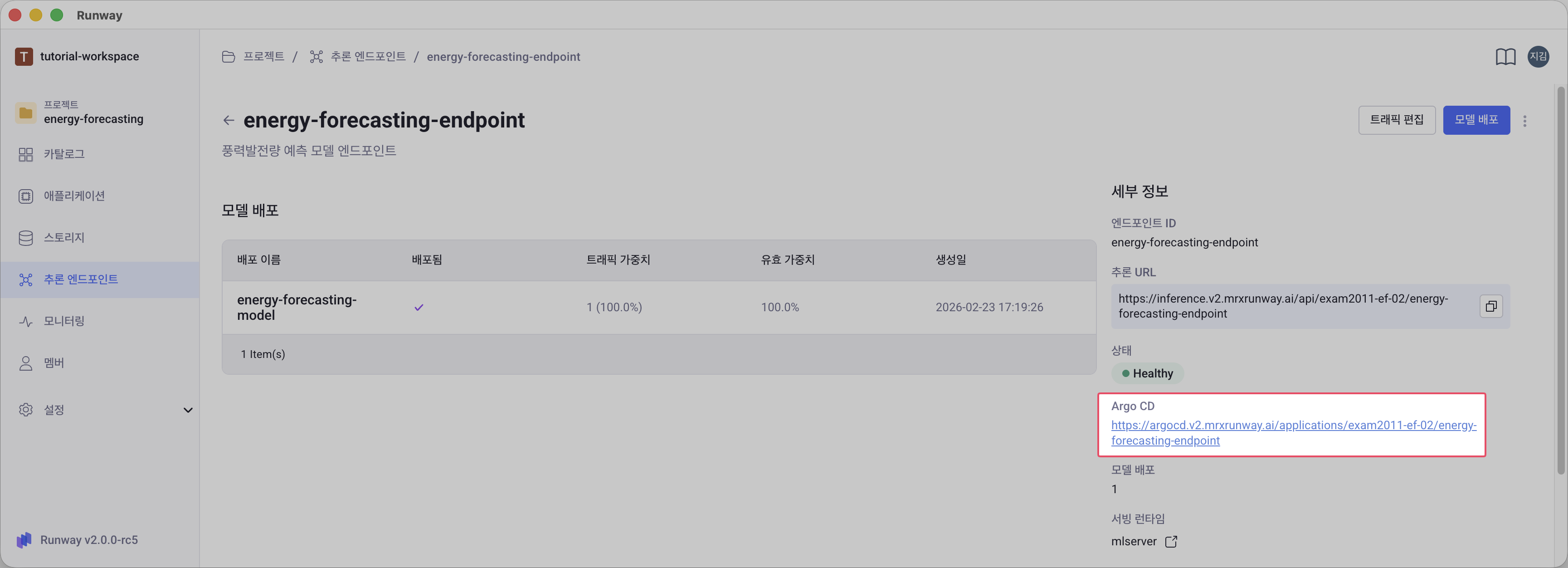
배포된 모델 상태 확인
배포된 모델의 상태는 엔드포인트 상세 화면에서 ArgoCD 링크를 통해 확인할 수 있습니다.
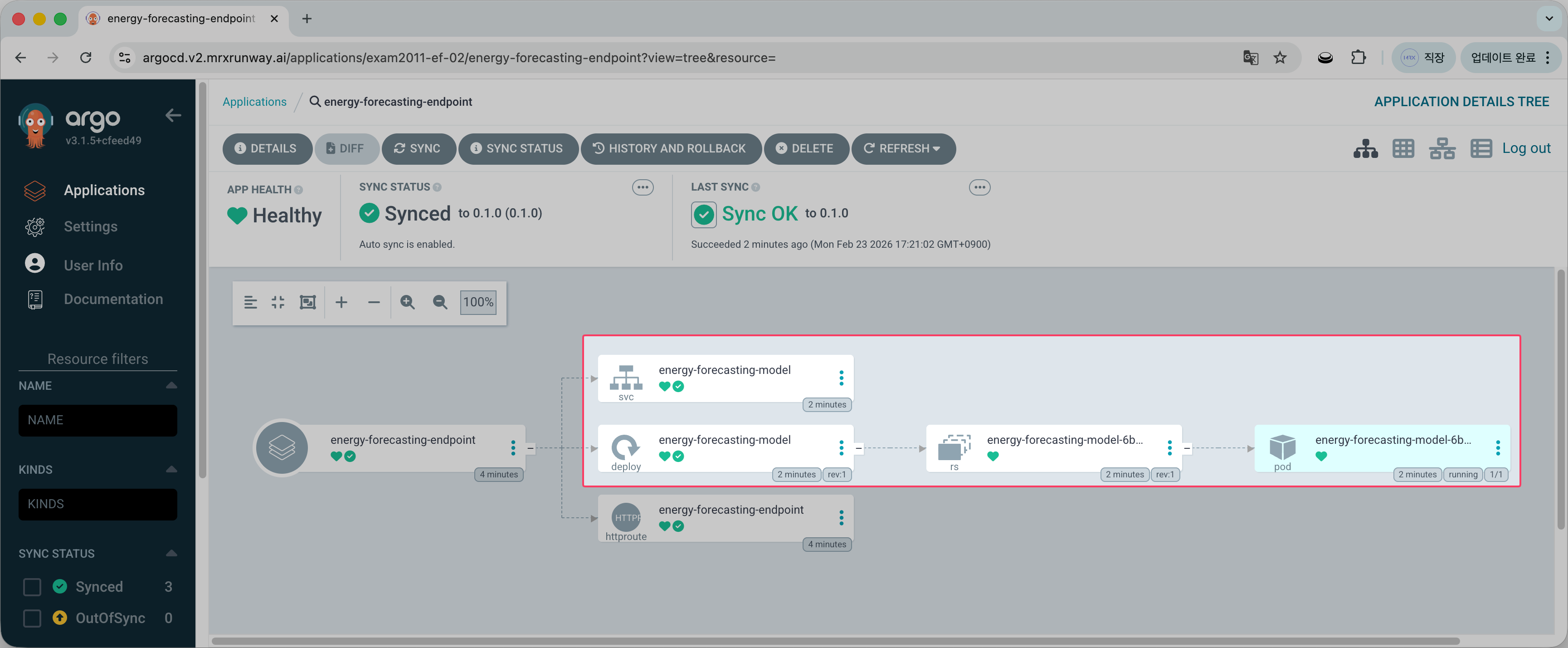
ArgoCD 링크를 클릭하면 엔드포인트 내에 배포된 모델의 상세 상태를 확인할 수 있습니다.
모델 추가 배포¶
하나의 엔드포인트에 여러 모델을 배포하여 다양한 배포 전략을 실행할 수 있습니다.
사용 사례
| 배포 전략 | 설명 | 트래픽 설정 예시 |
|---|---|---|
| A/B 테스트 | 두 모델 버전의 성능을 비교하여 최적의 모델 선택 | 모델 A: 50%, 모델 B: 50% |
| 점진적 롤아웃 | 기존 모델에서 새 모델로 트래픽을 점차 이동 | 기존: 70% → 50% → 30% → 0% 신규: 30% → 50% → 70% → 100% |
| 섀도우 테스트 | 새 모델에 요청을 복제하여 비동기로 검증 | 프로덕션: 100%, 테스트: 0% (로깅만) |
배포 방법
모델 추가 배포 절차는 모델 배포 생성과 동일합니다.
단, 트래픽 설정 단계에서 기존 배포된 모델과 새로 배포할 모델 간 트래픽 가중치를 조정합니다.
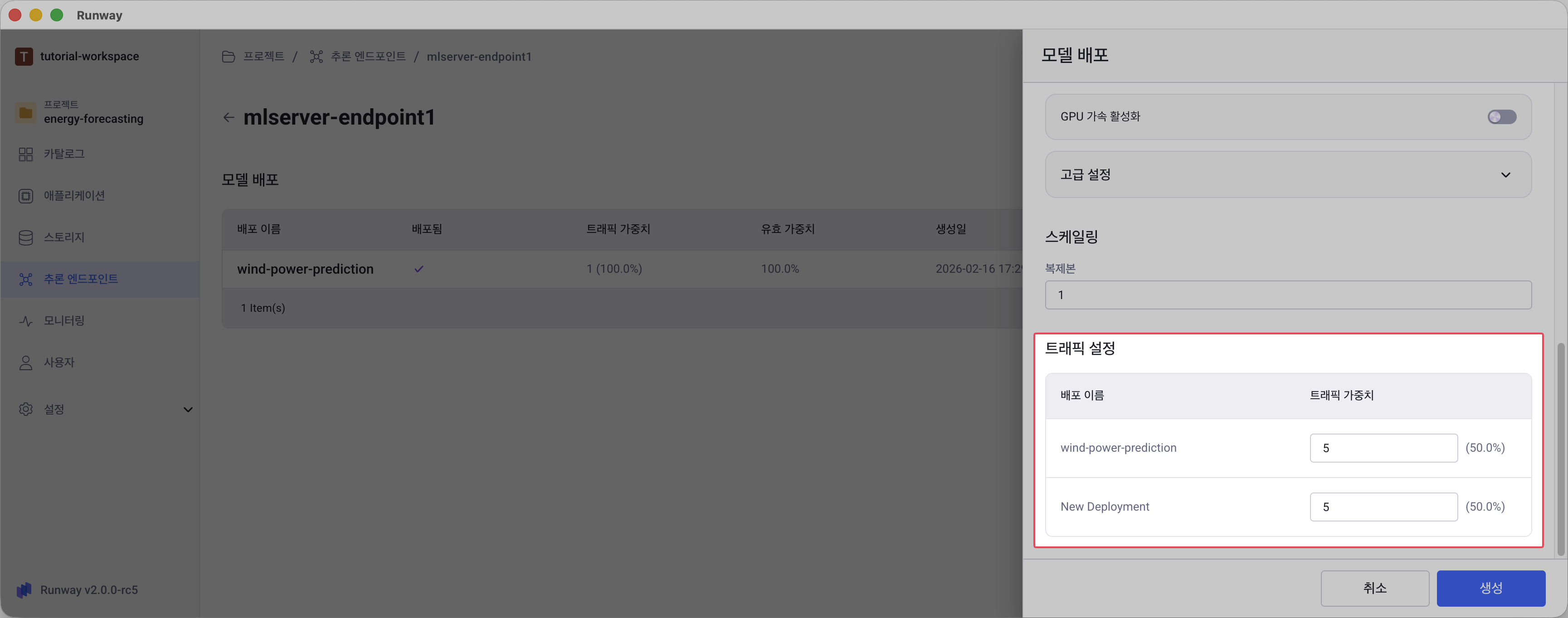
트래픽 가중치 설정
여러 모델이 배포된 경우, 각 모델의 트래픽 가중치를 입력하여 요청 분배 비율을 제어합니다.
가중치 계산 방식
- 각 모델의 비율 = (해당 모델 가중치 ÷ 전체 가중치 합) × 100%
설정 예시
-
A/B 테스트 (50:50)
- 기존 모델: 가중치 1 → 비율 50%
- 새 모델: 가중치 1 → 비율 50%
-
점진적 롤아웃 (70:30)
- 기존 모델: 가중치 7 → 비율 70%
- 새 모델: 가중치 3 → 비율 30%
-
카나리 배포 (90:10)
- 프로덕션 모델: 가중치 9 → 비율 90%
- 카나리 모델: 가중치 1 → 비율 10%
배포 후 트래픽 조정 및 유효 가중치
모델 배포 생성 후에도 트래픽 분배 관리를 통해 언제든지 트래픽 비율을 조정할 수 있습니다.
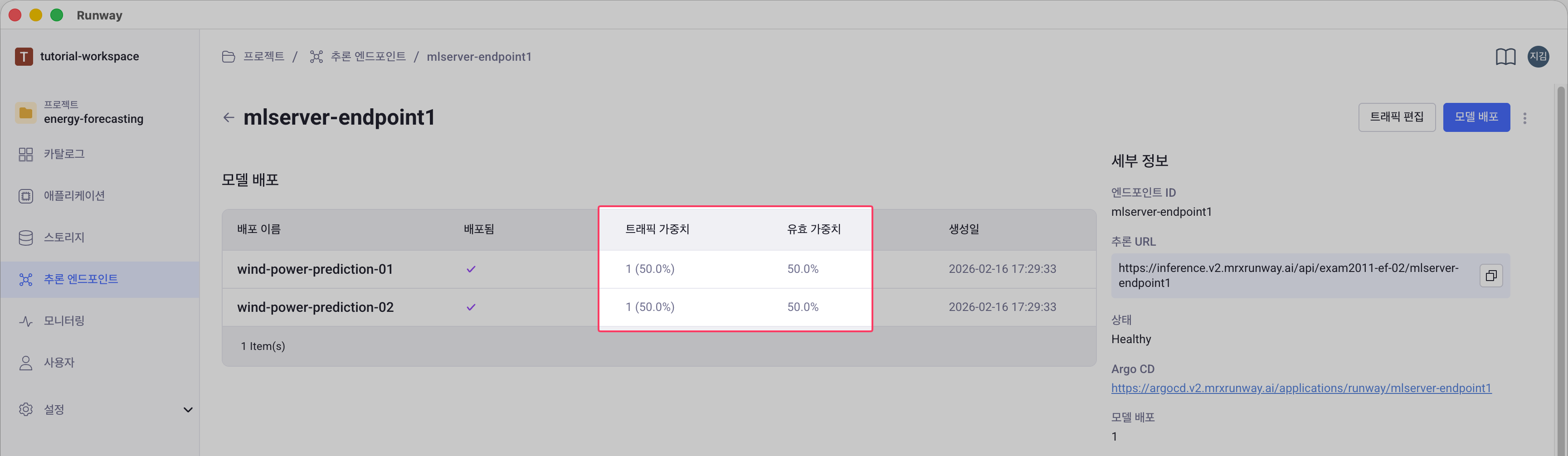
유효 가중치(Effective Weight)는 실제 트래픽이 라우팅되는 비율입니다. 미배포 상태이거나 오류가 있는 모델은 제외하고, 정상 배포된 모델만을 기준으로 100%로 정규화한 값입니다. 엔드포인트 상세 화면의 모델 목록에서 각 모델의 사용자가 지정한 트래픽 가중치와 실제 트래픽인 유효 가중치를 함께 확인할 수 있습니다.
트래픽 분배를 통한 배포 전략¶
엔드포인트에 배포된 여러 모델 간 추론 요청 트래픽을 분배하는 비율을 설정합니다.
트래픽 분배란?
엔드포인트로 들어오는 추론 요청을 여러 배포 모델에 어떤 비율로 라우팅할지 결정하는 기능입니다.
A/B 테스팅, 카나리 배포, 점진적 롤아웃 등의 배포 전략에 활용할 수 있습니다.
가중치 시스템
트래픽 분배는 상대적 가중치(Relative Weight) 방식으로 동작합니다:
- 입력 값: 0 이상의 정수로 각 배포의 상대적 가중치를 설정
- 비율 계산: (해당 배포 가중치 ÷ 전체 가중치 합) × 100%
- 표시 형식: 가중치 (비율%) — 예: 7 (63.6%)
트래픽 분배 설정
엔드포인트 내에서 이미 배포된 2개 이상의 모델 간의 트래픽 분배를 조정합니다.
-
프로젝트 화면에서 추론 엔드포인트 메뉴로 이동합니다.
-
엔드포인트 목록에서 원하는 엔드포인트를 선택합니다.
-
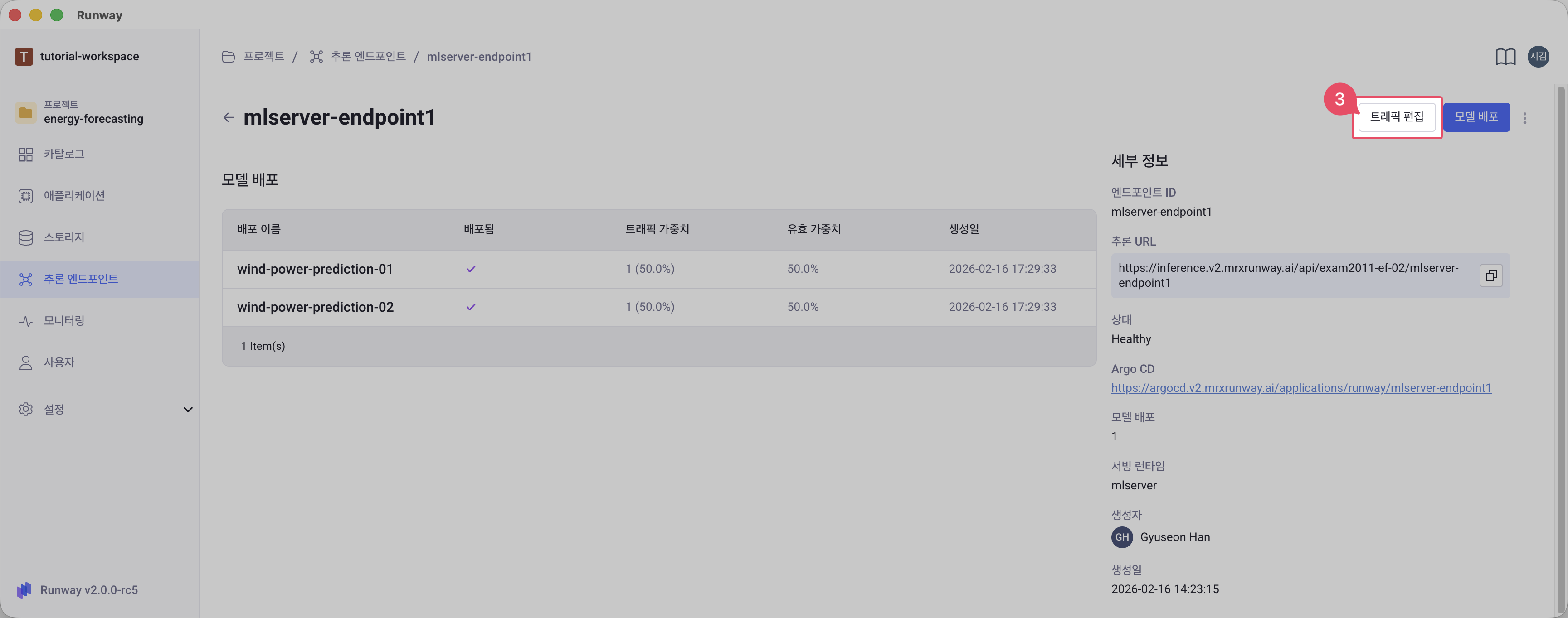
모델 배포 탭에서 오른쪽 상단의 트래픽 편집 버튼을 클릭합니다.
-
트래픽 분배 모달에서 각 배포 모델의 가중치를 설정합니다.
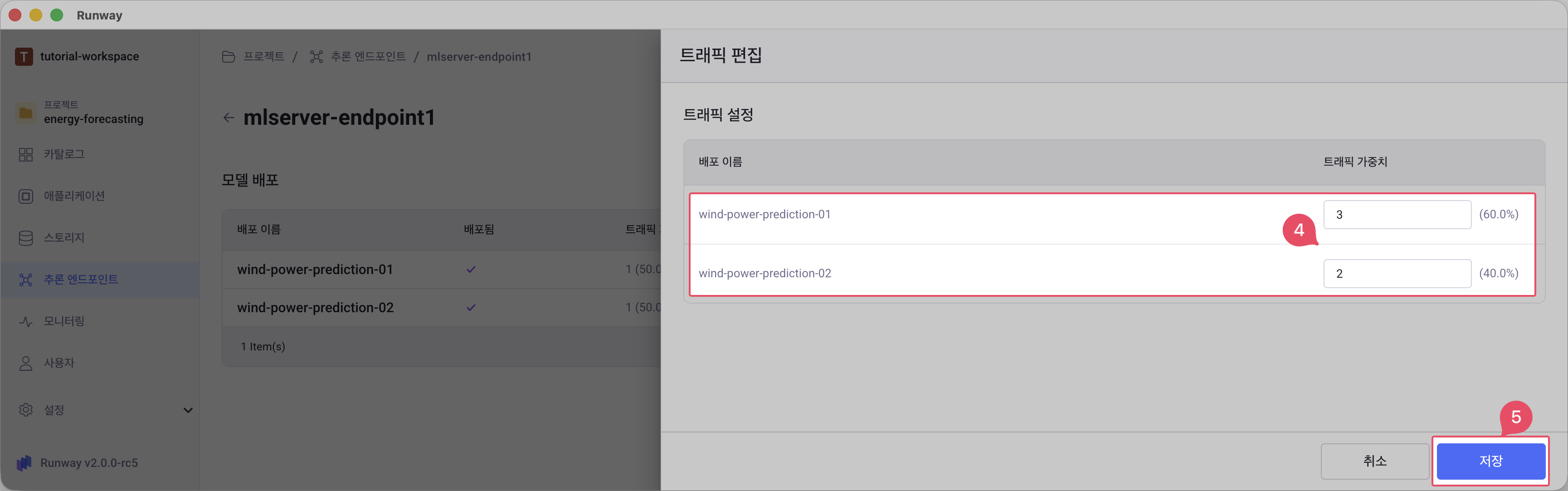
- 각 배포의 Traffic Weight 입력 필드에 원하는 가중치 값을 입력합니다.
- 입력한 가중치에 따라 계산된 비율이 자동으로 표시됩니다.
-
저장 버튼을 클릭하여 변경사항을 적용합니다.
트래픽 분배 권장사항
- 새 모델을 배포할 때는 작은 가중치(예: 1)부터 시작하여 점진적으로 증가시키는 것이 안전합니다.
- 가중치를 0으로 설정하면 해당 배포로 트래픽이 전혀 전달되지 않습니다.
- 모든 배포의 가중치를 0으로 설정할 수 없습니다. 최소 하나의 배포는 0보다 큰 가중치를 가져야 합니다.
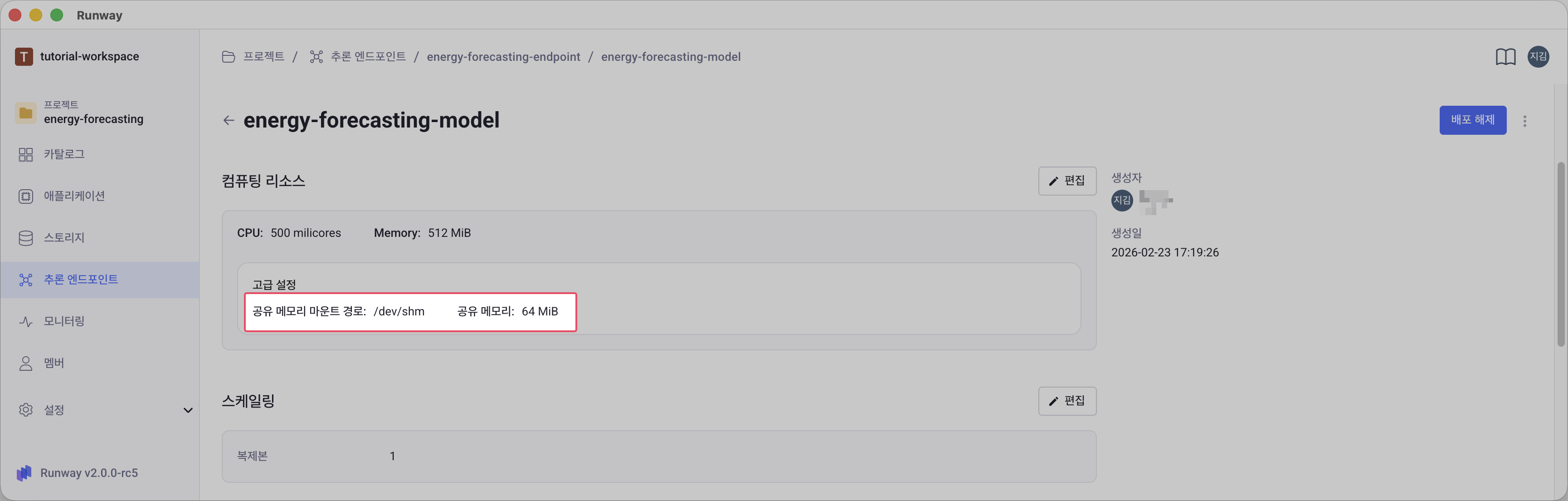
공유 메모리(Shared Memory) 설정¶
공유 메모리(Shared Memory)는 컨테이너 내부의 프로세스 간 데이터를 빠르게 공유하기 위한 메모리 영역입니다. 모델 배포에 할당된 메모리 중 일부를 공유 메모리로 할당할 수 있습니다. 모델 배포 생성 시 컴퓨팅 리소스 영역 하단의 고급 옵션에서 공유 메모리를 설정할 수 있습니다.
다음과 같은 경우에 공유 메모리 설정이 필요합니다:
- PyTorch DataLoader의
num_workers > 0사용 시 (멀티프로세스 데이터 로딩) - 멀티프로세스 기반 추론 파이프라인 사용 시
- NVIDIA Triton의 shared memory 기반 데이터 전달 사용 시
설정 항목
| 항목 | 설명 | 기본값 | 제약 조건 |
|---|---|---|---|
| 공유 메모리 마운트 경로 | 공유 메모리가 마운트되는 파일시스템 경로 | /dev/shm |
슬래시(/)로 시작해야 함 |
| 공유 메모리 크기 (MiB) | 할당할 공유 메모리 용량 | 64 MiB | 할당된 Memory 값을 초과할 수 없음 |
설정 방법¶
-
모델 배포 생성 화면에서 컴퓨팅 리소스 영역 하단의 고급 옵션을 펼칩니다.
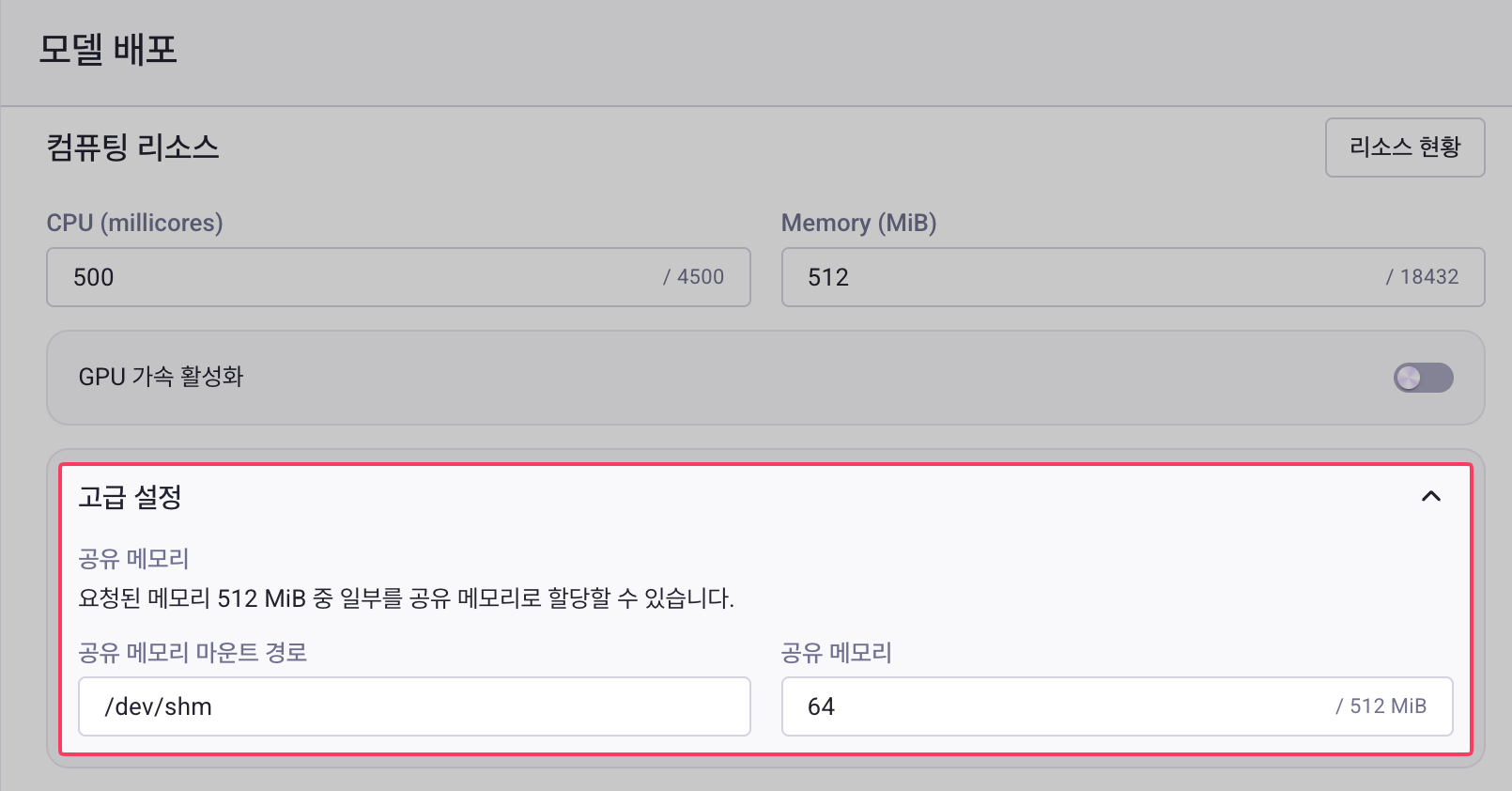
-
공유 메모리 마운트 경로를 입력합니다.
- 대부분의 경우 기본값
/dev/shm을 그대로 사용합니다.
- 대부분의 경우 기본값
- 공유 메모리 크기를 MiB 단위로 입력합니다.
- 입력 필드 우측에 현재 할당된 Memory 대비 최대값이 표시됩니다 (예:
/ 2048 MiB).
- 입력 필드 우측에 현재 할당된 Memory 대비 최대값이 표시됩니다 (예:
공유 메모리 크기 제한
공유 메모리는 컴퓨팅 리소스에서 할당한 Memory 용량 이내에서만 설정할 수 있습니다. 예를 들어, Memory를 2048 MiB로 설정했다면 공유 메모리는 최대 2048 MiB까지 할당 가능합니다.
배포 후 확인¶
배포된 모델의 상세 화면 > 컴퓨팅 리소스 영역 > 고급 설정에서 설정된 공유 메모리 마운트 경로와 크기를 확인할 수 있습니다.